Wpływ indeksacji na wydajność wyszukiwania w bazie MySQL
Wszyscy wiemy, że stosowanie indeksów przyśpiesza wyszukiwanie i podnosi wielkość tabel spowalniając modyfikacje. Artykuł pokazuje jak profilować zapytania i mierzyć ilościowe aspekty wpływu indeksów na wydajność wyszukiwania.


Wyszukiwanie po kluczu jest szybsze niż wyszukiwanie po zwykłym atrybucie. Nic odkrywczego. Jednak byłem ciekaw jakiego rzędu są to różnice. Przygotowałem eksperyment.
W tym artykule przedstawię porównanie szybkości wyszukiwania po kluczu głównym z wyszukiwaniem po nie indeksowanym atrybucie. Zobaczę jak na wydajność wyszukiwania wpływa przeniesienie tabeli do pamięci operacyjnej. Oraz przeanalizuję wyniki za pomocą oprogramowania Mathematica.
Skład kodu
46% MySql 54% Mathematica
Baza danych
Zaczniemy od standardowego nagłówka zapewniającego idempotentność. W MySql jest to dość proste
DROP DATABASE IF EXISTS test;
CREATE DATABASE IF NOT EXISTS test;
USE test;
Tworzymy jedną tabelę z kluczem oraz zwykłym atrybutem
CREATE TABLE main(
id INTEGER UNIQUE NOT NULL AUTO_INCREMENT PRIMARY KEY,
value INTEGER
);Procedury zapisu danych
Definiujemy procedurę wypełniającą tabelę danymi
drop procedure if exists load_data;
delimiter #
create procedure load_data(IN _max INTEGER)
begin
declare counter int unsigned default 0;
truncate table main;
start transaction;
while counter < _max do
set counter=counter+1;
insert into main (value) values (counter);
end while;
commit;
end #
delimiter ;Najpierw usunęliśmy procedurę o tej nazwie, jeśli już istniała. W kolejnej linii ustawiliśmy znak końca komendy na #. Dzięki temu definiowanie procedury nie zostanie przerwane w środku przez występujące tam średniki. Naszą procedurę nazwaliśmy load_data i posiada ona jeden argument całkowitoliczbowy - liczbę wierszy jakimi wypełni tabelę. Linia zaczynająca się od declare odpowiada za ustawienie zmiennej lokalnej przechowującą nasz licznik. Przed rozpoczęciem transakcji czyścimy tabelę którą będziemy wypełniać. Wewnątrz transakcji wykonuje się pętla zapisująca do tabeli wartości od 1 do _max. Na końcu używamy znaku # jako średnika i przywracamy średnikowi jego domyślne znaczenia. Całkiem sporo kodu jak na tak prostą operację. Jednak zysk z tego jest taki, że teraz wystarczy wpisać np.:
call load_data(5);a tabela wypełni się danymi zgodnie z naszymi oczekiwaniami
SELECT * FROM main;
+----+-------+
| id | value |
+----+-------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
+----+-------+
5 rows in set (0,00 sec)Ta procedura jest bardzo wygodna, bo pozwala ustawić dowolny rozmiar tabeli, ale ponieważ będziemy testować duże tabele i często podnosić ich rozmiary dodamy bardziej ograniczoną, ale wydajniejszą w naszym przypadku procedurę, która nie usuwa tablicy, a zamiast tego dopełnia ją danymi do podanego rozmiaru.
drop procedure if exists add_data;
delimiter #
create procedure add_data(IN _max INTEGER)
begin
declare counter int unsigned;
SELECT COUNT(*) INTO counter FROM main;
start transaction;
while counter < _max do
set counter=counter+1;
insert into main (value) values (counter);
end while;
commit;
end #
delimiter ;Nie ma tu już czyszczenia dotychczasowej zawartości tabeli. Counter nie przyjmuje wartości domyślnej 0, za to użyliśmy instrukcji SELECT ... INTO ... która wynik selektu przypisuje do zmiennej.
Teraz wykonanie call add_data(5) nie zmieni stanu naszej tabeli, ale po wykonaniu call add_data(10) rezultat będzie taki sam jak po call load_data(10) tyle, że oszczędziliśmy czas na usuwanie i wstawianie 5 wierszy, które już tam były.
Performance Schema
Zarówno w mysql jak i w mariadb do badania wydajności zapytań służy jest baza performance_schema. Może się okazać, że jej używanie jest wyłączone. Sprawdzimy to dzięki zmiennej performance_schema.
SELECT @@performance_schema;Jeśli jest stawiona na wartość 0 należy w pliku konfiguracyjnym:
sudo nvim /etc/my.cnf.d/server.cnfdodać linię:
performance_schemaw sekcji:
[mysqld]następnie zrestartować bazę danych poleceniem
sudo systemctl restart mysqlJeśli SELECT @@performance_schema; zwraca 1 oznacza to, że aktywowaliśmy ten mechanizm, ale nie jest to równoważne z możliwością wykonywaniem pomiarów, których potrzebujemy. Mechanizm zbierania logów może być bardzo rozbudowany i musimy go skonfigurować samodzielnie ze względów wydajnościowych.
Na przegląd aktualnych ustawień pozwolą nam zapytania o setup_consumers
SELECT NAME,ENABLED FROM performance_schema.setup_consumers;+----------------------------------+---------+
| NAME | ENABLED |
+----------------------------------+---------+
| events_stages_current | NO |
| events_stages_history | NO |
| events_stages_history_long | NO |
| events_statements_current | NO |
| events_statements_history | NO |
| events_statements_history_long | NO |
| events_transactions_current | NO |
| events_transactions_history | NO |
| events_transactions_history_long | NO |
| events_waits_current | NO |
| events_waits_history | NO |
| events_waits_history_long | NO |
| global_instrumentation | YES |
| thread_instrumentation | YES |
| statements_digest | YES |
+----------------------------------+---------+oraz o instrumentacje z tabeli setup_instruments
SELECT NAME,ENABLED,TIMED FROM performance_schema.setup_instruments;wyników jest bardzo dużo więc ograniczymy się do tych:
SELECT NAME,ENABLED,TIMED FROM performance_schema.setup_instruments WHERE NAME LIKE '%long%';+------------------------------------------------------------------+---------+-------+
| NAME | ENABLED | TIMED |
+------------------------------------------------------------------+---------+-------+
| statement/com/Long Data | YES | YES |
| memory/performance_schema/events_stages_history_long | YES | NO |
| memory/performance_schema/events_statements_history_long | YES | NO |
| memory/performance_schema/events_statements_history_long.tokens | YES | NO |
| memory/performance_schema/events_statements_history_long.sqltext | YES | NO |
| memory/performance_schema/events_transactions_history_long | YES | NO |
| memory/performance_schema/events_waits_history_long | YES | NO |
+------------------------------------------------------------------+---------+-------+
Chcemy doprowadzić do sytuacji w której po wykonaniu zapytania:
select * from main WHERE value=5;odpytują o
SELECT TIMER_WAIT FROM performance_schema.events_statements_history_long;zobaczymy zmierzony czas trwania ostatniego zapytania.
Aby to uzyskać włączymy konsumentów events_statements_history_long oraz events_statements_current zapytaniem:
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME = 'events_statements_current' OR NAME = 'events_statements_history_long';Teraz dla zapytania:
SELECT * FROM performance_schema.setup_consumers;powinniśmy zobaczyć:
+----------------------------------+---------+
| NAME | ENABLED |
+----------------------------------+---------+
| events_stages_current | NO |
| events_stages_history | NO |
| events_stages_history_long | NO |
| events_statements_current | YES |
| events_statements_history | NO |
| events_statements_history_long | YES |
| events_transactions_current | NO |
| events_transactions_history | NO |
| events_transactions_history_long | NO |
| events_waits_current | NO |
| events_waits_history | NO |
| events_waits_history_long | NO |
| global_instrumentation | YES |
| thread_instrumentation | YES |
| statements_digest | YES |
+----------------------------------+---------+A po wykonaniu
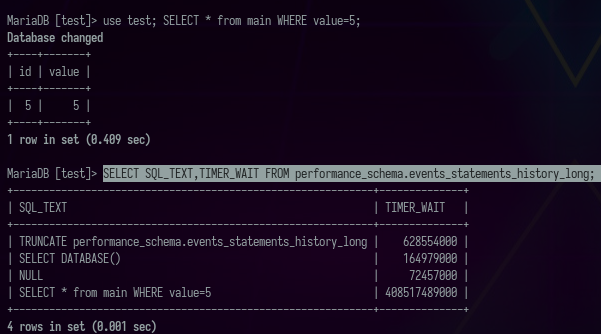
use test; SELECT * from main WHERE value=5;a następnie
SELECT SQL_TEXT,TIMER_WAIT FROM performance_schema.events_statements_history_long;
powinniśmy zobaczyć czas trwania zapytania wyrażony w pikosekundach
Jeśli temat konfiguracji mechanizmu profilowania Cię zainteresował możesz pogłębić wiedzę bezpośrednio w dokumentacji:
Procedura testująca (InnoDB)
Wykonamy teraz testy. Interesują nas czasy wykonywania selektów po id oraz po value.
select * from main WHERE id=5;
select * from main WHERE value=5;
Pierwszy z nich nazwiemy time_id drugi time_val, liczbę wierszy nazwiemy counter. Wyniki testów będziemy chcieli później przetwarzać, dlatego stworzymy dla nich specjalną tabelę.
CREATE TABLE IF NOT EXISTS result (
counter INTEGER PRIMARY KEY,
time_id DECIMAL(10,6),
time_val DECIMAL(10,6)
);Za jej wypełnianie odpowiedzialna będzie procedura, którą rozbijemy na kilka części. Oto jej początek.
drop procedure if exists time_of_select;
delimiter #
create procedure time_of_select(IN _max INTEGER, IN _step INTEGER)
begin
declare counter int unsigned DEFAULT 0;
declare temp_id int unsigned DEFAULT 0;
declare temp_value int unsigned DEFAULT 0;
declare time_id DECIMAL(10,6);
declare time_val DECIMAL(10,6);Zaczyna się jak wszystkie pozostałe - czyści dla siebie miejsce, ustawia znak nowej komendy na # wybiera sobie nazwę, argumenty i deklaruje zmienne lokalne. Argumenty to maksymalna wielkość tabeli dla jakiej chcemy testować, oraz krok jaki ma wykonywać nasz licznik. Zmienne lokalne służą do iteracji - counter, zapobiegają wyświetlaniu nie potrzebnych danych temp_id i temp_value, oraz przechowują wyniki pomiarów czasu - time_id i time_val. Następnie jest czyszczenie tabel.
truncate table result;
call load_data(0);Zauważ, że call load_data(0) jest równoważne komendzie truncate table main. Po wyczyszczeniu wszystkich danych możemy zacząć przebieganie pętli
while counter < _max do
set counter=counter+_step;
call add_data(counter);Podnosimy licznik i dodajemy wiersze do tabeli main.
truncate performance_schema.events_statements_history_long;
RESET QUERY CACHE;Czyścimy historię pomiarów wydajności i resetujemy cache.
select * INTO temp_id, temp_value from main WHERE id=counter;
select * INTO temp_id, temp_value from main WHERE value=counter;Wykonujemy selekty które chcemy testować. Żeby nie zaśmiecały nam ekranu przekierowujemy je do lokalnych zmiennych, z którymi już nic nie będziemy robić. Teraz najciekawsza część - mierzenie wydajności:
SELECT TRUNCATE(TIMER_WAIT/1000000000000,6) INTO time_id
FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like '%id=%';
SELECT TRUNCATE(TIMER_WAIT/1000000000000,6) INTO time_val
FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like '%value=%';Jest to nowa zalecana metoda na mierzenie wydajności ponieważ SET profiling = 1; jest już zdeprecjonowany. Mając wszystkie potrzebne parametry dopisujemy je do tabeli result, wyświetlamy je i kończymy definiowanie procedury w standardowy sposób.
INSERT INTO result (counter, time_id, time_val) VALUES (counter,time_id,time_val);
SELECT counter/_max "state", counter, time_id, time_val;
end while;
end #
delimiter ;Dokładnie 4 godziny, 40 minut zajęło mi wykonanie procedury call time_of_select(25000000,10000), czyli wykonywanie pomiarów dla tabeli o rozmiarach od 10 tysięcy do 25 milionów rekordów z krokiem 10 tysięcy.
Testowanie silnika MEMORY
Żeby móc wrócić do tych danych i bez żadnych zmian w kodzie procedur wykonać pomiar na tabeli trzymanej w pamięci RAM przepiszemy nasze wyniki do nowej tabeli.
CREATE TABLE IF NOT EXISTS innoDB_result (
counter INTEGER PRIMARY KEY,
time_id DECIMAL(10,6),
time_val DECIMAL(10,6)
) AS SELECT * FROM result LIMIT 2500;
Oraz postawimy naszą tabelę result od nowa tym razem w pamięci RAM.
DROP TABLE main;
CREATE TABLE main(
id INTEGER UNIQUE NOT NULL AUTO_INCREMENT PRIMARY KEY,
value INTEGER
) ENGINE=MEMORY;Jeśli w tym momencie włączyli byśmy procedurę testującą, to po 8 sekundach dostali byśmy następujący błąd:
ERROR 1114 (HY000): The table 'main' is fullJest tak dlatego, że domyślnie MySQL ma ustawiony rozmiar tabel w pamięci RAM na 16 MB. Możemy to sprawdzić wpisując
SELECT max_heap_table_size;Zmienimy go komendą:
SET max_heap_table_size = 2048*1024*1024;Która na wszelki wypadek ustawi 2 GB RAM dla bazy danych. I tu pojawia się pytanie, skąd wziąłem akurat 2 GB. Szczerze przyznam, że nie wiedziałem w momencie pisania tego artykułu. Ta tabela na dysku zajmowała u mnie 930.72 MB, więc myślałem, że w 1 GB RAM powinna się zmieścić, ale okazało się, że po zapisaniu w pamięci operacyjnej jej rozmiar to aż 1538.54 MB. Zadałem na ten temat pytanie na stacku. Okazało się, że InnoDB przechowuje dane w BTree a MEMORY w Hash, co znacząco obniża możliwość kompresji kluczy w tabeli trzymanej w pamięci RAM. Teraz testy powinny pójść gładko. Możemy ponownie uruchomić procedurę do testowania.
call time_of_select(25000000,10000)Tym razem test trwał 46 minut.
Tabela main nie będzie nas już interesować. Aby zwolnić pamięć możemy ją usunąć.
DROP TABLE main;Po tych operacjach mamy następującą sytuację: w bazie zostały dwie tabele z wynikami innoDB_result dla silnika innoDB oraz result dla silnika MEMORY. Do ich analizy nie będziemy wykorzystywać już MqSQL. Możemy zamknąć połączenie z bazą.
Analiza wyników
Do analizy danych wykorzystamy program Mathematica firmy Wolfram Research. Z tego programu można korzystać na dwa sposoby - pisząc w notebookach (coś jak brudnopis) i pisząc paczki oraz skrypty wykonywalne z konsoli. Paczki i skrypty są to czyste pliki tekstowe, które nadają się do trzymania w repozytorium. Notebooki niestety nie. Notebooki nadają się do rozbudowy kodu i liczenia czegoś, co ma zostać policzone jeden raz, a paczki i skrypty do wielokrotnego użytku i automatyzacji. W naszym przypadku odpowiednim narzędziem będzie notebook. Zaczynamy więc pisanie w nowym notebooku.
Wizualizacja danych z bazy
Aby połączyć się z bazą danych importujemy odpowiednią paczkę.
Needs["DatabaseLink`"]I ustawiamy zmienną zawierającą połączenie
conn = OpenSQLConnection[
JDBC["MySQL(Connector/J)", "127.0.0.1:3306/test"],
"Username" -> "root", "Password" -> ""]Wyciągamy z bazy interesujące nas dane.
counterTimeIdInnoDB = SQLExecute[conn, "SELECT counter, time_id FROM innoDB_result"];
counterTimeValInnoDB = SQLExecute[conn, "SELECT counter, time_val FROM innoDB_result"];
counterTimeIdMemory = SQLExecute[conn, "SELECT counter, time_id FROM result"];
counterTimeValMemory = SQLExecute[conn, "SELECT counter, time_val FROM result"];I od razu przechodzimy do rysowania wykresu.
ListPlot[{counterTimeIdInnoDB, counterTimeIdMemory},
PlotLabel ->
"Time of SELECT using PRIMARY KEY for InnoDB and MEMORY engines for \
different number of rows.",
PlotLegends ->
Placed[SwatchLegend[{"InnoDB", "MEMORY"},
LegendMarkerSize -> {30, 30}], {0.5, 0.25}],
AxesLabel -> {"Rows", "Time[s]"} , BaseStyle -> {FontSize -> 14},
ImageSize -> 1200]
Export["plotId.png", %];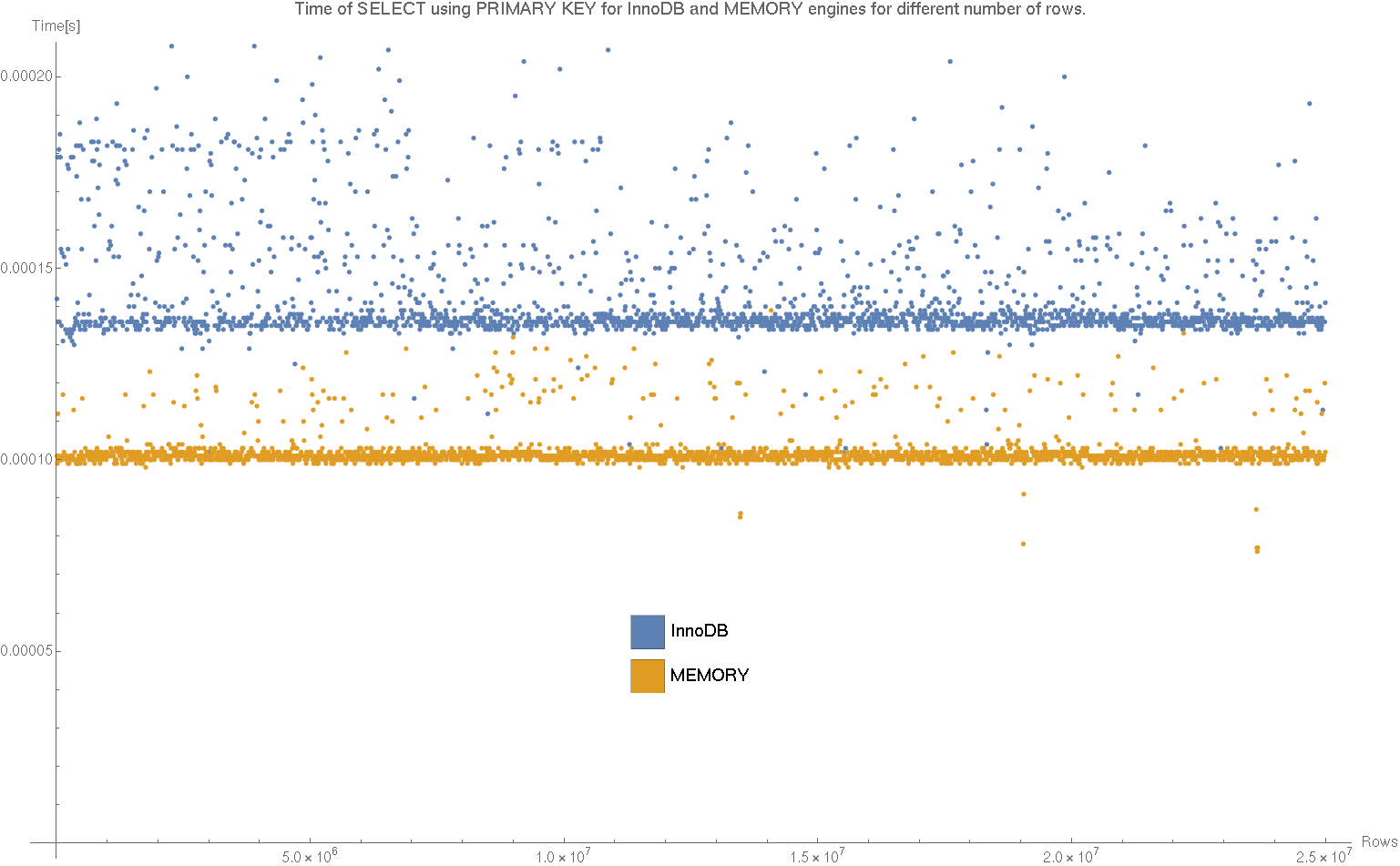
Widzimy, że zarówno dla InnoDB jak i MEMORY szybkość wybierania po identyfikatorze nie zależy od ilości rekordów w bazie dla naszego zakresu. Na pewno nie jest to zależność, którą można by wyłowić z szumu, który jest tutaj obecny. Widać, że dla tabeli w pamięci operacyjnej selekty są wykonywane szybciej, a czas ich wykonywania jest bardziej regularny. Zupełnie inaczej sytuacja wygląda dla nie indeksowanych atrybutów.
ListPlot[{counterTimeValInnoDB, counterTimeValMemory},
PlotLabel ->
"Time of SELECT using not indexed attribute for InnoDB and MEMORY \
engines for different number of rows.",
PlotLegends ->
Placed[SwatchLegend[{"InnoDB", "MEMORY"},
LegendMarkerSize -> {30, 30}], {0.5, 0.25}],
AxesLabel -> {"Rows", "Time[s]"} , BaseStyle -> {FontSize -> 14},
ImageSize -> 1200]
Export["plotVal.png", %];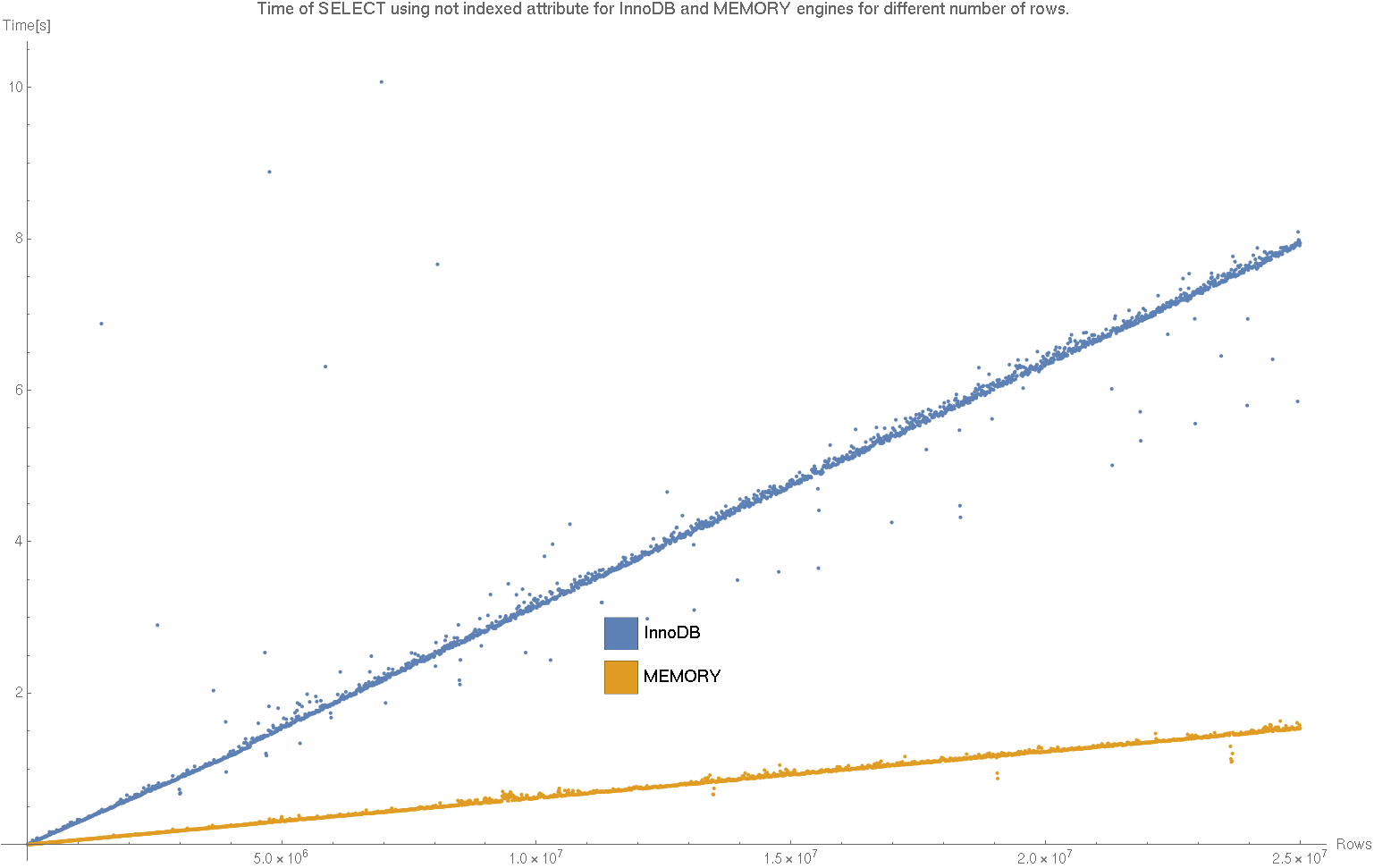
Czas wybierania nie indeksowanego atrybutu rośnie liniowo z wielkością bazy. Tu również tabela zapisana w pamięci operacyjnej działa szybciej.
Dzięki dopasowaniu prostej poleceniem Fit[counterTimeValInnoDB, {x}, x] widzimy, że współczynnik kierunkowy dla tabeli na dysku to 3.06e-7, co oznacza, że na milion rekordów przypada 0.3 sekundy wyszukiwania. Obliczając współczynnik kierunkowy dla silnika MEMORY poleceniem Fit[counterTimeValMemory, {x}, x] otrzymamy 6.46e-8, czyli 0.06 sekundy na milion rekordów, a więc 4.7 raza krócej.
Histogram
Wróćmy do wybierania po kluczach. Ponieważ w tamtym przypadku zależność od czasu nie była widoczna, zredukujmy tą zmienną przyjrzyjmy się histogramowi przedstawiającemu liczbę zliczeń których czas wykonywania mieścił się w określonym przedziale. Za rysowanie odpowiada poniższy kod.
timeIdInnoDB = Transpose[counterTimeIdInnoDB][[2]];
timeIdMemory = Transpose[counterTimeIdMemory][[2]];
Histogram[{Flatten[timeIdInnoDB],
Flatten[timeIdMemory]}, {90, 180, 1}*10^-6,
PlotLabel ->
"Histogram of times of select by PRIMARY KEY for different times \
(from 90\[Mu]s to 180\[Mu]s with step 1\[Mu]s)",
AxesLabel -> {"Time[s]", "Count"} ,
ChartLegends ->
Placed[SwatchLegend[{"InnoDB", "MEMORY"},
LegendMarkerSize -> {30, 30}], {0.5, 0.75}],
BaseStyle -> {FontSize -> 14},
ChartStyle -> ColorData[97, "ColorList"], ImageSize -> 1200]
Export["histogram.png", %];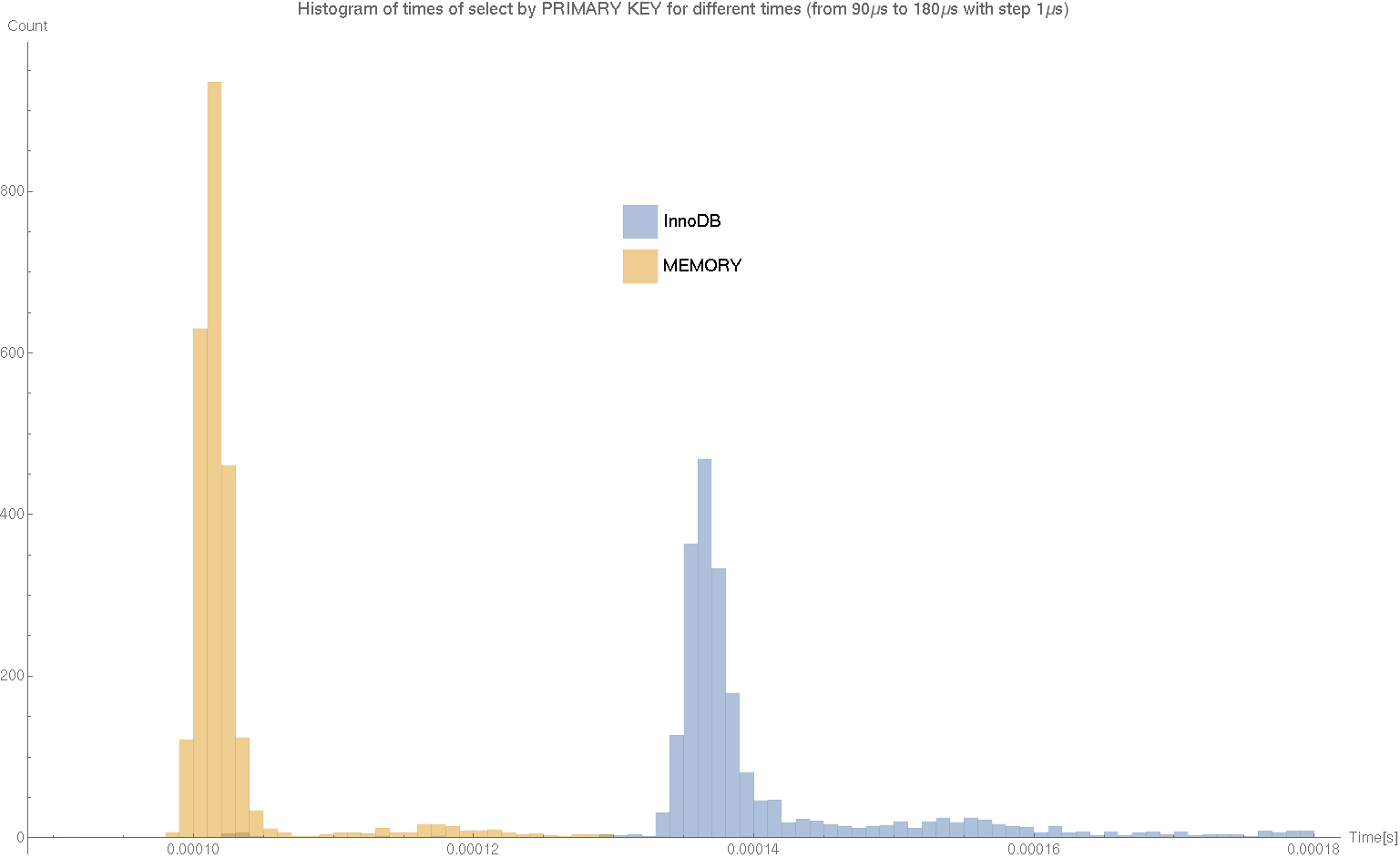
Model
Nie znam wystarczająco dobrze mechanizmu odpowiadającego za ten rozkład. Jego znajomość pozwoliła by mi wybrać odpowiedni model matematyczny, który można by dopasować do danych. Z tego względu dalsza część to dopasowanie rozkładu, który tylko z grubsza przypomina ten rzeczywisty. Zaczynamy od wycięcia danych do dopasowywania modelu.
dataInnoDB = Transpose[{Range[0.5, 299.5],
BinCounts[Flatten[timeIdInnoDB], {0, 300, 1}*10^-6]}];
dataMemory = Transpose[{Range[0.5, 299.5],
BinCounts[Flatten[timeIdMemory], {0, 300, 1}*10^-6]}];Te tablice zawierają czas przeliczony na mikrosekundy oraz odpowiadające chwilom czasu liczby zliczeń. Przesunięcie o 0.5 wynika z tego, że punktowi 0.5 odpowiada przedział od 0 do 1. Następnie postulujemy model.
model = c HeavisideTheta[x - a] (x - a)*Exp[-b (x - a)];Jak wspomniałem nie jest to model wywnioskowany z właściwości niskopoziomowej implementacji baz danych, a jedynie pierwszy prosty model jaki mi przyszedł do głowy. Kiedy mamy dane i model zostało tylko wyliczyć jego współczynniki. Odpowiadają za to linie:
lineInnoDB =
FindFit[dataInnoDB, model, { {a, 120}, {b, 0.2}, {c, 100} }, x]
lineMemory =
FindFit[dataMemory, model, { {a, 100}, {b, 0.8}, {c, 100} }, x]Współczynniki, które otrzymaliśmy to odpowiednio
{a -> 126.08, b -> 0.212895, c -> 102.94}dla InnoDB oraz
{a -> 99.4551, b -> 0.836701, c -> 1587.85}dla MEMORY. Pozostało tylko wyrysowanie wykresu porównującego dopasowane krzywe z danymi doświadczalnymi. Do łączenia wykresów różnych typów służy polecenie Show, jego składnia jest następująca:
Show[ListPlot[{dataInnoDB, dataMemory}, Filling -> Axis,
PlotRange -> All, PlotMarkers -> {"\[FilledCircle]", 4},
PlotLegends ->
Placed[SwatchLegend[{"InnoDB", "MEMORY"},
LegendMarkerSize -> {30, 30}], {0.5, 0.75}]],
Plot[{model /. lineInnoDB, model /. lineMemory}, {x, 0, 300},
PlotRange -> All], AxesLabel -> {"Time[\[Mu]s]", "Count"},
PlotLabel ->
"Histogram of times of selects execution with curves fitted for \
model c HeavisideTheta[x-a](x-a)*Exp[-b(x-a)]",
BaseStyle -> {FontSize -> 14}, ImageSize -> 1200]
Export["model.png", %]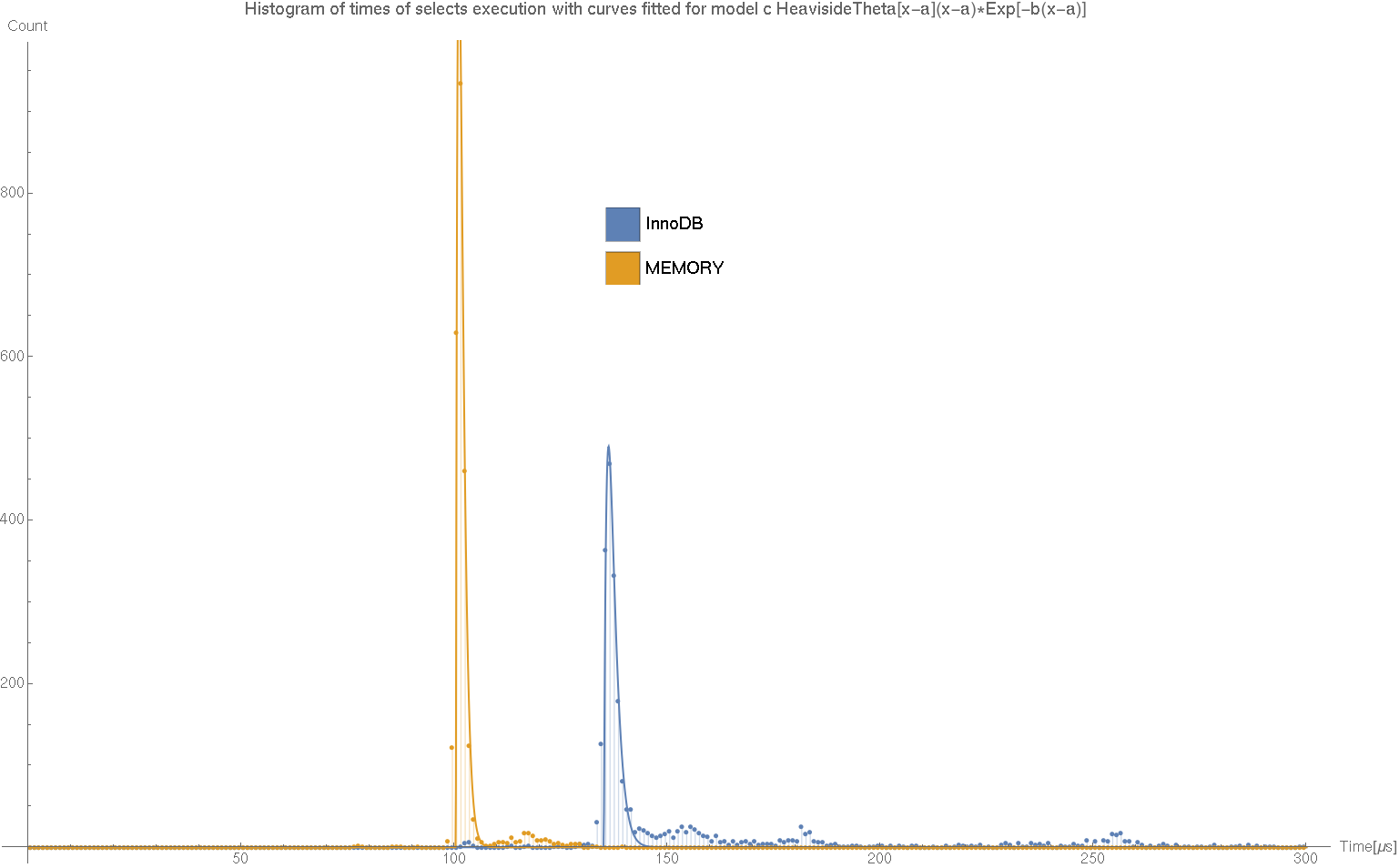
To dopiero początek mojej przygody z bazami danych i wciąż temat ten jest znany mi tylko pobieżnie. Z tego względu wpisy dotyczące baz należy taktować bardziej jako notatki ucznia, niż wskazówki eksperta. Mimo to, mam nadzieję, że czas poświęcony na czytanie przełożył się u Ciebie na lepsze wyczucie ilościowych aspektów związanych z wydajnością indeksowania.
Na koniec dziękuję Rickowi Jamesowi za odpowiedzi na praktycznie każde pytanie, jakie do tej pory zadałem na dba.stackexchange.com.